
計算機・並列化(MS-MPI)
現在工事中です。
過去の2010年に、Argonne National LaboratoryのサイトでMPICH2をダウンロードし、Fortranで組んだテストプログラムを並列実行した経験がある。
今回は最新版(2013年11月時点)のMPICH(注1)をダウンロードし、Windows環境でFortran言語による並列計算プログラムを実行するまでの経過を以下紹介する。
【注1】2010年当時は"MPICH2"と末尾に"2"がついていたが、今回サイトを閲覧すると"2"がなくなっている。 なお、2010年のダウンロードファイルは、"mpich2-1.2.1p1-win-ia32.msi"および"mpich2-1.2.1.p1-win-x86-64.msi"というファイルをダウンロードしていた。
MPIツールとして、今回MicrosoftのWindows版を使ったが、IntelのCluster Studio(有償)はMPIをサポートしており、Intelの方がメジャーなMPIなのかも知れない。 Linux版は、ANLのサイトでかなり更新されているようだが、MS-MPIは使用方法のドキュメントが整っていないため、試行錯誤のところがある。 過去2010年のMPICH2は、割合とドキュメントが揃っていて、すんなり実行できた。
機会があれば、IntelのCluster Studio(無償の評価版)を試してみたいと思う。
- 1. MPIについて
- 1.1 MPIのダウンロード
- 1.2 MPIとは
- 2. MS-MPIのインストール
- 3. 単一マシンの実行テスト
- 3.1 Fortranプログラム
- 3.2 Cプログラム
- 4. クラスタ構成で並列計算のテスト
- 4.1 コードのコンパイル・リンク
- 4.2 実行環境の設定
- 4.3 コードの実行
- 5. Fortranによる姫野ベンチマーク
- 5.1 コードのコンパイル・リンク
- 5.2 コードの実行結果
- 6. その他のMPI
- 6.1 Linux環境のMPICH
- 6.2 Open_MPI
- 6.3 Intel Cluster Studio
- 7. Literature Cited
【注】数式表示にはMathJaxを利用しています。IE8以下では表示が遅くなる可能性があります。FireFox などIE8以外のブラウザを利用下さい。
MPIについて
Windows版のMPIについて、またFortran言語から利用することを前提に概略を紹介する。
MPIのダウンロード
MPI(Message Passing Interface)を使った並列計算では、ネットワークで繋がった複数のマシンを使い、プログラムコードを分担・協調して実行し、実質的な計算時間を短くする並列化の手法である。 詳しくは、サイト http://www.mpich.orgを参照されたい。Stableな最新版は、現在 ver 3.0.4との記述がある。
mpich.orgのサイトから、WindowsのMPICHを選択すると、MicrosoftのHPC Packのサイト http://www.microsoft.com/en-us/download/details.aspx?id=39961にジャンプし、ダウンロードすることができる。 ダウンロードの際に、64bit版のmpi(mpi_x64.msi)および32bit版のmpi(mpi_x86.msi)の選択画面に以降し、チェックマークを入れることでファイル選択することができる。インストールするマシンのOSが64bitなら64bit版を、 32bitOSなら32bit版をダウンロードする。
並列計算に参加するすべてのマシンにmpichをインストールする必要がある。Windows XPもサポートしているので、32bit版XPマシンを使うときにはx86版もインストールしておく。
なお、Microsoft Teamの作ったmpichは、Microsoftのサイトでは"MS-MPI"と呼んでおり、以下MS-MPIを本サイトでも使う。
MPICHは、主にLinux OS上で利用されるようだが、ダウンロードサイトの最後のほうに Micfosoft MPI Teamが作ったMicrosoft Windows版(ver 1.0.3)が掲載されている。今回のインストールおよび実行テストでは このVer1.0.3をダウンロードし、インストールした。なおインストールしたマシンのOSは、Windows 7(64Bit,Ultimate,CPU:core i7)である。また並列実行のために利用したマシンは Windows 7 (64Bit, Ultimate, CPU: core i5)のノートマシンを用いた。
MPIとは
日本語のテキストとして、C言語からMPIを利用する秋葉訳、P.パチェコの図書1)、およびFortran言語からMPIを利用する樫山ら2)の図書がある。 MPIを使ったプログラムは、プログラマーがMPI関数を適切に利用し並列計算を考えながらコーディングしなければならず、コード 開発者にとってはハードルが高い。OpenMPのように自動化が難しい面がある。 逆に、プログラマーの裁量により、高速な並列化プログラムが書ける自由度があるといえる。
ネットワークを通して、メッセージをやり取りすることから、スパコンのような高性能なマシンに仕上げるには 高速で特殊なネットワークが必要となるが、イーサネットでも原理的には利用可能である。
現時点では、並列化のメリットがある技術計算としては、流体解析などのような大規模計算 が思い浮かぶ。これ以外の化学工学の計算でクラスタ構成のマシンを使って並列計算を実行しなければならない 負荷の重い課題(蒸留計算などの反復計算にしても負荷が重いとは言い難い)はすぐには思いつかない。 最適化手法で、遺伝的アルゴリズムのように、数多くのメンバーに同じ処理をさせる計算には向いているが、問題により負荷の軽重があろう。 しかしいずれ、PCの低廉化により分散環境が当たり前になると考えられ、今のうちに基礎を整えておき、利用分野の拡大を視野に入れておく必要がある。
MS-MPIのインストール
ここでは、Windows 7(64bitOS)のマシンに、MS-MPIをインストールすることを前提に解説する。 またFortran(後の並列計算の実行テストで使う)は、Intel Parallel Studio XE 2013を用いる。 インストールマシンには、MS Visual Studio 2010がすでにインストールされているが、 Visual Studio経由でFortranコードを作成せず、Command Promptベースでコンパイル、リンクを実行することを前提に解説する。
並列計算に参加させるマシンのすべてにMS-MPIをインストールする必要があり、以下のインストール手順をすべてのマシンで実行する。
【ステップ1】msi_x64.msiを右クリックで、インストールを開始する。Welcomeスクリーン、Copyrightsスクリーンを経由して インストールフォルダを指定する。
【ステップ2】フォルダはデフォルトのまま、あるいはユーザ指定でも可能。ハードドライブを指定する。SDカードドライブなどは不可。
このフォルダに、以下のサブフォルダが作られる。
\Bin: mpiexec.exe, smpd.exeなどの実行可能ファイルがインストールされる
\Inc: mpi.f90, mpi.hなどヘッダファイルがインストール
\Lib\amd64: amd64用のライブラリファイルがインストール
\Lib\i386: i386用のライブラリファイルがインストール
【ステップ3】インストールボタンをクリックし、インストールを開始する。
【ステップ4】環境変数を確認する。コントロールパネル「システム」の「システムの詳細設定」-「環境変数」を 選択し、システム環境変数の "Path"に、上のステップ2で指定したフォルダが追加されていることを確認する。 追加されていなければ、編集し、手動で追加する。
ver 1.0.3のMS-MPIは、自動的に環境変数Pathを設定してくれるようだ。MPICH2では手動で設定していた。
【ステップ5】環境変数を更新するため、マシンを再起動する。
【ステップ6】再起動後、「アクセサリ」-「コマンドプロンプト」またはIntel FortranのCommand Promptを選択し、 コマンドプロンプトから、c:\>mpiexec.exe /? を実行する。実行結果を図1(注)に示す。
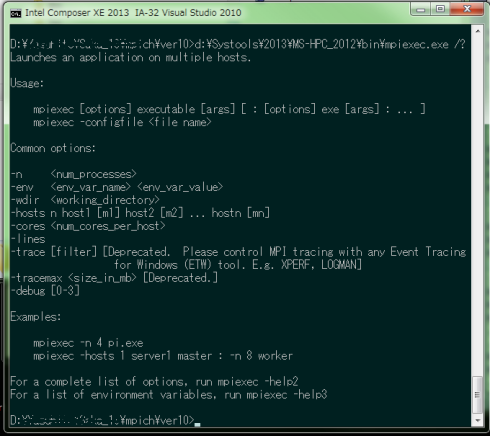
図1:mpiexecのpathを確認
(注)Intel Parallel Studioをインストールしていると、Intel社のmpiexec.exeファイルが実行されることがある。 この場合の例として、図2に -version スイッチをつけたときの実行結果を示す。

図2:mpiexec(Intel社)
Intel社のmpiexecが実行される(設定したPathでIntelのPathが先に指定されている)とき、図1のようにMS-MPIをインストールしたフォルダ指定してmpiexec.exeを実行すればよい。
以上で、MS-MPIのインストールと環境設定が終わったことになる。ヘッダファイル、ライブラリファイルの利用方法は次章で述べる。
単一マシンの実行テスト
MS-MPIをインストールした直後の、単一のマルチコアCPUマシン(core i7, 920) でMPIコードの実行テストを実施しました。 言語は、Fortranと C言語で試しています。コードの中身は図書1),2)で紹介されているように簡単なものです。
Fortranプログラム
もっとも簡単なMPIを利用したFortranプログラムのコードをリスト1に示す。 また、コンパイル、リンク、実行を含むメイクファイルをリスト2に示す。 利用するFortranコンパイラーは、Intel Visual Fortran Ver 13.1.1.171を利用した。
なお、リスト1のコード中のコメントにあるように、コマンド"mk"は、バッチコマンド mk.batで、 "nmake /f %1.mak %2"と定義している。なお、nmake.exeはVisual Studio付属のコマンドである。
Fortranコード中の、MPI_XXXXが、MPIルーチンを示している。MPI関連のヘッダファイルとして、Fortran用の"MPIF.H"をINCLUDEしている。
変数MPIに、MS-MPIをインストールしたディレクトリを定義し、INCLUDEファイルの所在を、FOR_OPT2変数に設定している。 またMPI用のライブラリファイルを、LIBS変数で"msmpifmc.lib"、"msmpi.lib"の2つを設定している。
実行時は、オプション"run"をつけることで、mpiexec.exeをフラグ"-n 4"つきでTEST11.EXEを実行する。 フラグ"-n 4"はプロセッサー数を4つ使うことを意味している。この段階ではサーバーマシン上の4つのプロセスを起動している。
まだネットワークを介して、クラスター構成のマシン群を利用していない。 この段階では、OpenMPの並列化と大きな差はない。明示的にMPIルーチンをFortran文として指定することがMPIの特徴である。 一方、OpenMPではディレクティブと呼ばれる、Fortran文法にはない構文を用い、コードに並列化用の指示を与えている。
mpiexecを経由しないで実行した結果(test11.exeをコマンドプロンプトで直接実行)と、 mpiexecを経由し、ノード数4に設定して実行した結果を図3に示す。
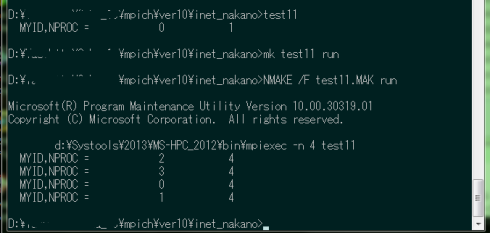
図3:TEST11の実行結果
test11.exeの直接実行では、ランク0のプロセスが1つである。一方 "mk test11 run"でmpiexec経由で実行すると、 ランクが2,3,0,1の合計4つのプロセスが起動されていることがわかる。
なお、Windows 7上で実行するとき、ファイアウォールでブロックされるというセキュリティの警告が出力される。 出力例を図4に示す。このメッセージに対し”アクセスを許可”すると実行を継続する。
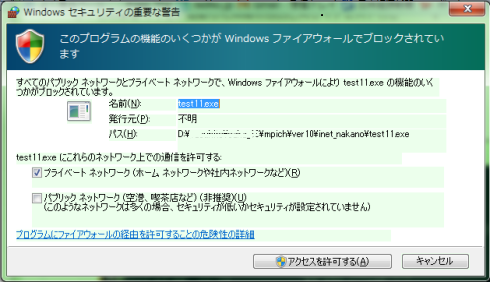
図4:TEST11の実行時のセキュリティ警告
また、ウィルス対策ソフトで、実行時に実行を拒絶される可能性がある。avast!では拒絶されるため、実行ファイルをウィルス検索対象から除外するソフトに追加し、 実行可能なように設定する必要があった。実行可能ファイルのあるフォルダを丸ごと除外するよう図5の(1)の部分にフォルダ名を追加している。
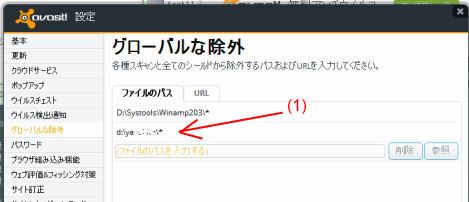
図5:avast!のウィルス保護の解除画面
avast!の場合、MPIコードを実行するといきなりウィルスチェストという場所に隔離されてしまう。ウィルスチェストを開き、復元し、上のグローバル除外指定しないと 起動するたびに隔離されてしまう。他のウィルス対策ソフトの場合は経験ないので不明。
Cプログラム
リスト1のFortran言語のサンプルをC言語に変えただけの簡単なプログラムです。 コードをリスト3に示します。
ファイアウォール警告などはFortranコードと全く同じ。
同様にC言語ソースのコンパイル、リンク、実行用のメイクファイルをリスト4に示す。 コンパイラーは、Intel Composer XEに付属するC言語コンパイラー icl.exeを利用している。
メイクファイルの構成は、Fortranの場合とほぼ同様である。実行結果は図3とほとんど同じであり掲載を省略する。
クラスタ構成で並列計算のテスト
次に、複数のマシンをネットワークで結んだクラスター構成の場合の、MPIによる並列計算のサンプルを以下に示す。
2010年当時、MPICH2を用いた並列計算サンプルを、今回のMS-MPIで実行するため、更新したFortranコードを リスト5に示す。複数のプロセスを、複数のマシンで並列起動させるテストコード(プログラム名:test12)である。
コードのコンパイル・リンク
実行モジュールtest12.exeは、リスト6に示す、ユーザー作成のモジュール(M_MOD1)を使用している。
test12.exeは、複数のプロセスを起動し、ランクが0のプロセスが入力ファイルから1行のテキストを読み込み、 プロセスIDと起動プロセス数をファイル出力し、読み込んだテキストをファイル出力する。
リスト5、6に示すコードの、メイクファイルをリスト7に示す。
コンパイル・リンクはコマンドプロンプトから、
\>mk test12
を実行する。クリーンアップは、同じく
\>mk test12 clean
を実行する。ここで、"mk"は、nmake.exeのバッチコマンドで前述と同じである。
実行可能モジュールtest12.exeを実行するとき、以下の実行形態を選択できる。各実行形態の詳細はリスト7を参照されたい。
| \>mk test12 run | mpiexecを使わない、singleプロセス実行 |
| \>mk test12 run0 | サーバーマシン上で、4プロセス並列実行 |
| \>mk test12 run1 | サーバーマシン上で、singleプロセス実行 |
| \>mk test12 run2 | host指定、singleプロセス実行 |
| \>mk test12 run3 | host指定、2マシン指定、各2プロセス並列実行 |
| \>mk test12 run4 | マシンファイル指定、4プロセス並列実行 |
リスト7のメイクファイルで、test12.exeの実行のまえに、前回の出力ファイルを削除(del log.txt)を行い、その後実行し、 結果のlog.txtを画面出力(type log.txt)して、結果を確認している。
実行環境の設定
単独マシンで実行する、リスト7のrun、run0、run1では環境を設定することなく、コンパイル直後にコンパイルしたマシン上で そのまま実行させることができる。
一方、クラスター環境でコードをサーバー側から起動する前に、次のようにクライアント側の環境をあらかじめ設定しておく必要がある。
- 1)MS-MPIのインストーラーをクライアントマシンで作成し、PATHを通しておく
- 2)サーバー側のディレクトリ構造と全く同じディレクトリ構造をクライアント側にも作成しておく
- 3)クライアント側のコードを保存したディレクトリを共有設定し、サーバーからアクセス可能にする
- 4)サーバー側の実行可能ファイルおよび必要なファイルをクライアント側にコピー
実行可能ファイル、マシンファイルなどクライアント側でも使う - 5)サーバー側、およびクライアント側で、smpd.exeデーモンを起動しておく
- 6)サーバー側から、mpiexecコマンドでコードを実行する
リスト7で、run2、run3、run4を起動させるとき、マシン名を直接またはマシンファイル(mfile.txt)を通して、 プロセスを起動するマシンを指定している。マシン名を名前解決とクラスタ並列計算のためのデーモンsmpd.exe(MS-MPIに 付属する。mpiexec.exeと同じ\Binフォルダにある)を、予め起動しておく必要がある。smpd.exeの ヘルプ画面および起動画面をリスト8に示した。ポート番号は8677を使っている(らしい)。 この辺りのマニュアルが見当たらず、エラーメッセージなどから推察した。
2010年当時のMPICH2では、デーモンsmpd.exeの起動停止はオプションスイッチ(-start, -stop)をつけることによりできた。MS-MPIでは ヘルプ画面を見ると、これらスイッチがなくなっている。
マシンファイルのサンプルを、リスト9に示す。先頭の"#"はコメント行、1行にマシン名を1つ記述し、 複数のマシンを利用するときは、その行数分を記述する。以前のMPICH2では、マシン毎に起動するプロセス数 を、"マシン名:n"のように指定することができた。しかし、MS-MPIではマシン名のみで、起動プロセス数を指定 するとエラーが発生する。
各マシンでどれだけのプロセスが生成されるのかは、現時点では判明していない。トータルのプロセス数は mpiexecの引数で指定することができるが、マシンファイルを使う場合には指定できない。マシンに割り振るプロセス数 を指定したいときには、run3のような記述で、mpiexecに引数を渡す方法しかないのかもしれぬ。
なお、テスト環境のクラスタ構成(Windows 7マシン2台)を図6に示す。サーバー・マシン(マシン名:i7_920、CPU:core i7)と、 クライアント・マシン(マシン名:note_sx2、CPU:core i5)を、同一ドメイン"workgroup"に繋いでいる。なお、note_sx2は 無線LAN経由で、ブリッジを経由し、有線LANのハブと接続している。
i7_920は、IntelのCore i7 CPUを搭載し、4コア8スレッドのプロセスを、note_sx2は、Intelの Core i5 CPUを搭載し、2コア4スレッドのプロセスを起動できる。
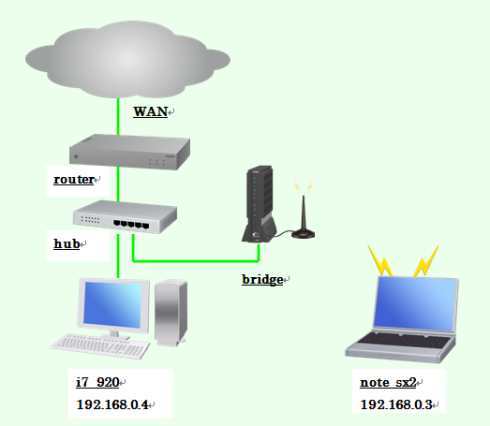
図6:クラスタ・マシン群のネットワーク構成
たまたま自宅のマシン環境で、note_sx2を無線LANを使っていたので、そのまま無線LANで構築した。有線LANの方が 計算速度が速いと思われる。またHub、router経由で外部WAN(インターネット)に接続するが、この部分は並列計算 とは無関係で、サーバー側マシンi7_920とクライアント側のnote_sx2がethernet経由で TCP/IPで接続されていればよい。なお図中のIPアドレスは同じドメインに属している。
コードの実行
実行結果は、run, run0, run1は、単独マシン上で予想通りの結果が得られている。 run2は、同じく単独マシン上で4つのプロセスを起動し、正常終了している。
run3は、i7_920上で2つ、note_sx2上で2つ、合計4つのプロセスが起動し、正常終了している。 run4も、結果としてrun3と同じく、各マシンで2つのプロセスが起動し、正常終了している。 このときの、タスクマネージャによるCPUの使用率を図7および図8に示す。 i7_920マシンでは5つのスレッドの中の4つが同じピーク高さを示しており、これが並列計算に 利用されたプロセスと考えられる。一方note_sx2マシンではピーク高さがほぼ同じ2つのスレッド が見られ、並列計算に利用されたプロセスと考えられる。
これらタスクマネージャによる図では、並列計算が瞬間的に終了してしまい、本当に並列計算を実行 しているか判別がつきにくい。
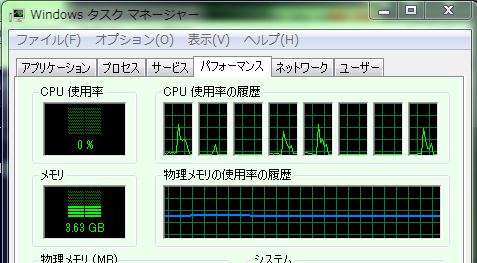
図7:タスクマネージャによる確認(i7_920)
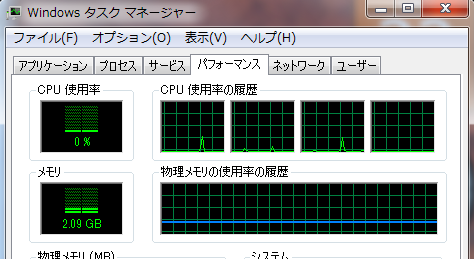
図8:タスクマネージャによる確認(note_sx2)
そこでもう少し計算負荷を上げたテストコードで試すことにした。
Fortranによる姫野ベンチマーク
独立行政法人 理化学研究所の姫野氏が、MPIコードを用いた数値計算ベンチマークコードを 姫野ベンチマーク3)として公開している。現在公開されているコードで、Fortran77の サイズM(256x128x128)のコード(現在のファイル名 himenoBMTxp_m.f)とほぼ同等の、2010年当時に ダウンロードしたFortranソースコードを用いて、並列計算を実行した。
コードの内容は三次元ポアッソン方程式を、ヤコビの反復法で解く、並列計算の評価のためのコードで、 ベンチマークのテスト結果も公開されている。
コードのコンパイル・リンク
Fortranソースコードの掲載(ファイル名はhimenoBMTxpr.fとしている)は省略する。
最適化コンパイルオプションは /Od (最適化無効)とし、コンパイルした。
コマンドプロンプト上で、
\>mk test13
でコンパイルし、実行可能なモジュールtest13.exeが生成する。そして
\>mk test13 run1
などターゲット指定で実行できる。リンクファイル(test13.mak)をリスト10に示す。
コンパイル時のオプションで "/define:M222"は、姫野氏のサイズMコードに相当する配列サイズを
選択するフラグである。
コードの実行結果
実行のためのターゲットとして、次の5つをメイクファイルで用意した。
| \>mk test13 run | mpiexecを使い、2つのマシンでそれぞれ2プロセスを起動。 実行時エラー、"Invalid number of PE"でダウン。 |
| \>mk test13 run1 | mpiexecを使い、サーバーマシンで8プロセスを起動。 実行できた。 |
| \>mk test13 run2 | mpiexecを使い、マシンファイル指定で合計8プロセスを起動。 実行できた。各マシンとも4プロセスづつ起動 |
| \>mk test13 run3 | mpiexecを使い、note_sx2マシンのみで8プロセスを起動。 実行できた。2コア4スレッドで、8プロセスを実行している。 |
| \>mk test13 run4 | mpiexecを使い、2つのマシンで合計12プロセスを起動。 実行時エラー、"Invalid number of PE"でダウン。 |
このうち、run2およびrun4のマシンファイルは、リスト9と同じファイルを用いた。また 起動プロセス数の指定で、run2およびrun4で、2,4,12などを試したが、"Invalid number of PE"エラーで 計算しない。8を指定するrun3は実行できた。エラーの原因はよくわからない。
run1の実行中のタスクマネージャのCPU使用率を図9に示す。8プロセス(8スレッド)が起動している。
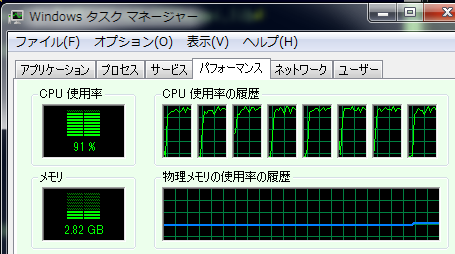
図9:test13.exe run1の実行中(i7_920)
同様に、run2(2つのマシンで合計8プロセス起動)のCPU使用率を図10、図11に示す。
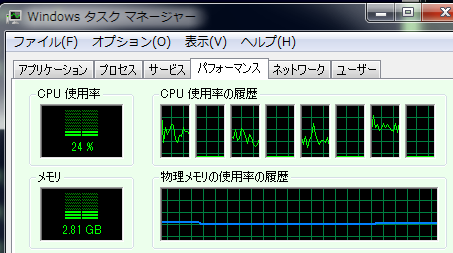
図10:test13.exe run2の実行中(i7_920)
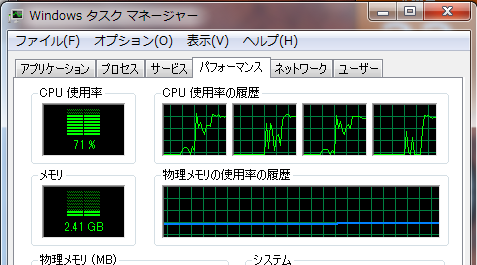
図11:test13.exe run2の実行中(note_sx2)
各マシン毎に4つづつプロセスが自動的に(というか勝手に)分配されている。分配方法の指定は不明である(マニュアル等が見当たらず、インターネットなど十分に調べていないため)。
run2をコマンドプロンプト上で実行したときの出力メッセージを図12に示す。およそ541MFLOPSの性能であることが判る。 Core i7(2.67GHz)とCore i5(2.60GHz)のクラスタ構成で、無線LAN経由のEthernet環境で、最適化オプションなしでこの 程度の性能となった。
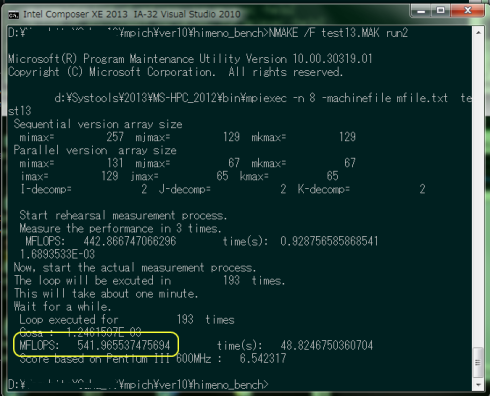
図12:test13.exe run2の出力(i7_920)
以上、クラスタ構成のマシン群を用いて、Windows環境下で、主にFortran言語を用いた 並列計算のさわりを紹介した。計算速度の向上のための、最適化コンパイル、ベクトル化、 OpenMPとの併用など課題は残されているが、手持ちのethernet環境でマシン群による並列計算が実行 出来ることが分かった。
その他のMPI
MS-MPI以外の、MPIコードをサポートする環境についてインターネットなどを調べた。その知見を以下紹介する。
Linux環境のMPICH
Linux環境で、MPICHが各種Linux Distribution用に無償配布されており、活発な開発が行われていて最新版を利用することができる。 Linuxを使っての動作テストは実施していないが、安価にクラスター並列計算を実行するとき、選択肢の一つであることに間違いない。 OSそのものが無償であり、MPICHもオープンソースで無償で利用可能であることはメリットが大きい。環境が整えばテストしたい。
Open_MPI
MPIに関してネット検索すると、Open_MPI(OpenMPではない)に関する情報が頻出する。Open_MPIの公式サイト http://www.open-mpi.org/のダウンロードページに、Windows版OpenMPI_v1.6.2-2?win64.exeなどが置いてある。 名前のとおりオープンソースであり、無償で利用できるらしい。今後機会があったらテストしてみたい。
ただし、サイト情報ではWindowsサポートはメンテする機関がなく、CygwinベースのOpenMPIを使えとリコメンドしている。
Intel Cluster Studio
Intel社のサポートするCluster Studioの利用が、Intel Fortranなどとの相性を考えると最もベストな選択なのであろう。Linux版とWindows版(HPC Server用)とがある。 しかし、ソフトは有償であり、個人ベースで購入するには高価である。お試し版がダウンロードできるので、いずれ時間があれば テストをしてみたい。
Literature Cited
関連ファイルのダウンロードは、こちら(未リンク)で取り扱っています。
- 参考図書・文献
- 1) P.パチェコ(秋葉訳):「MPI並列プログラミング」、培風館(2001).
- 2) 樫山、西村、牛島:「計算力学レクチャーシリーズ3 並列計算法入門」、丸善(2003).
- 3) 姫野ベンチマーク(理研):http://accc.riken.jp/2145.htm (2013年11月現在)